Introduction
In the previous post we learned how to implement a sample ordering service using the Akka-DDD framework. The service exposed the
The
The question arises, how to employ multiple offices to work on a business process and coordinate the workflow, so that the process is executed as defined by the business. To answer this question, we will first learn how to model a business process in a distributed system. Then we will review the implementation of a sample Ordering Process developed under the ddd-leaven-akka-v2 project. Finally we will see how Akka-DDD facilitates the implementation of business processes in a distributed system.
Reservation Office responsible for preparing and confirming the reservation of products, that the client added to their shopping cart. We learned that an office is a command handling business entity whose sole responsibility is to validate and process the commands. If the command validation succeeds, an appropriate event is written to the office journal.The
Reservation Office alone is obviously not able to execute the whole Ordering Process engaging activities like payment processing, invoicing and goods delivery. Therefore, to extend the functionality of the system we need to introduce two new subsystems / services: Invoicing and Shipping, that will be hosting Invoicing Office and Shipping Office respectively.The question arises, how to employ multiple offices to work on a business process and coordinate the workflow, so that the process is executed as defined by the business. To answer this question, we will first learn how to model a business process in a distributed system. Then we will review the implementation of a sample Ordering Process developed under the ddd-leaven-akka-v2 project. Finally we will see how Akka-DDD facilitates the implementation of business processes in a distributed system.
Business processes and SOA
To deliver a business value, an enterprise needs to perform its activities in a coordinated manner. Regardless of whether it is a production line or a decision chain, activities needs to be performed in a specific order accordingly to the rules defined by the business. The business process thus defines precisely what activities, in which order and under which conditions need to be performed, so that the desired business goal gets achieved.
The coordination of the activities implies the information exchange between the collaborators. In the past, business processes were driven by the paper documents flying back and forth between process actors. Nowadays, when more and more activities get performed by computers and machines, the business process execution is realized as a message flow between services. Unfortunately though, for a variety of reasons, the implementation of the Service-Oriented Architecture (SOA), very often ended up with a Big Ball of Mud as well as scalability and reliability issues (just to name a few) in the runtime.
The coordination of the activities implies the information exchange between the collaborators. In the past, business processes were driven by the paper documents flying back and forth between process actors. Nowadays, when more and more activities get performed by computers and machines, the business process execution is realized as a message flow between services. Unfortunately though, for a variety of reasons, the implementation of the Service-Oriented Architecture (SOA), very often ended up with a Big Ball of Mud as well as scalability and reliability issues (just to name a few) in the runtime.
The recent move towards the SOA 2.0 / Event-driven SOA / "SOA done Right" / Microservices (choose your favorite buzzword) enables delivering more light-weight, reliable / fault-tolerant and scalable SOA implementations. When it comes to modeling and executing business processes, the key realization is that since business processes are event-driven, the same events that get written to the office journals could be used to trigger the start or the continuation of business processes. If so, any business process can be implemented as an event-sourced actor (called Process Manager) assuming it gets subscribed to a single stream of events (coming from an arbitrary number of offices) it is interested in. Once an event is received, the Process Manager executes an action, usually by sending a command to an office, and updates its state by writing the event to its journal. In this way, the Process Manager coordinates the work of the offices within the process. What is important is that the logic of a business process is expressed in terms of incoming events, state transitions and outgoing commands. This seems to be a quite powerful domain specific language for describing business processes. Let's take a look at the definition of an sample Ordering Process, that is written using the DSL offered by the Akka-DDD:
Ordering Process - definition
startWhen {
case _: ReservationConfirmed => New
} andThen {
case New => {
case ReservationConfirmed(reservationId, customerId, totalAmount) =>
WaitingForPayment {
⟶ (CreateInvoice(processManagerId, reservationId, customerId, totalAmount, now()))
⟵ (PaymentExpired(processManagerId, reservationId)) in 3.minutes
}
}
case WaitingForPayment => {
case PaymentExpired(invoiceId, orderId) =>
⟶ (CancelInvoice(invoiceId, orderId))
case OrderBilled(_, orderId, _, _) =>
DeliveryInProgress {
⟶ (CloseReservation(orderId))
⟶ (CreateShipment(UUID(), orderId))
}
case OrderBillingFailed(_, orderId) =>
Failed {
⟶ (CancelReservation(orderId))
}
}
}
Source: OrderProcessManager.scala
An order is represented as a process that is triggered by the ReservationConfirmed event published by the Reservation Office. As soon as the order is created, the CreateInvoice command is issued to the Invoicing Office and the status of the order is changed to WaitingForPayment. If the payment succeeds (the OrderBilled event is received from the Invoicing office within 3 minutes) the CreateShipment command is issued to the Shipping Office and the status of the order is changed to DeliveryInProgress. But, if the scheduled timeout message PaymentExpired is received while the order is still not billed, the CancelInvoice command is issued to the Invoicing Office and eventually the process ends with a Failed status.
I hope you agree, that the logic of the Ordering Process is easy to grasp by looking at the code above. We simply declare a set of state transitions with associated triggering events and resulting commands. Please note that ⟵ (PaymentExpired(...)) in 3.minutes gets resolved to the following command: (⟶ ScheduleEvent(PaymentExpired(...), now + 3.minutes)) that will be issued to the specialized Scheduling Office.
startWhen {
case _: ReservationConfirmed => New
} andThen {
case New => {
case ReservationConfirmed(reservationId, customerId, totalAmount) =>
WaitingForPayment {
⟶ (CreateInvoice(processManagerId, reservationId, customerId, totalAmount, now()))
⟵ (PaymentExpired(processManagerId, reservationId)) in 3.minutes
}
}
case WaitingForPayment => {
case PaymentExpired(invoiceId, orderId) =>
⟶ (CancelInvoice(invoiceId, orderId))
case OrderBilled(_, orderId, _, _) =>
DeliveryInProgress {
⟶ (CloseReservation(orderId))
⟶ (CreateShipment(UUID(), orderId))
}
case OrderBillingFailed(_, orderId) =>
Failed {
⟶ (CancelReservation(orderId))
}
}
}
ReservationConfirmed event published by the Reservation Office. As soon as the order is created, the CreateInvoice command is issued to the Invoicing Office and the status of the order is changed to WaitingForPayment. If the payment succeeds (the OrderBilled event is received from the Invoicing office within 3 minutes) the CreateShipment command is issued to the Shipping Office and the status of the order is changed to DeliveryInProgress. But, if the scheduled timeout message PaymentExpired is received while the order is still not billed, the CancelInvoice command is issued to the Invoicing Office and eventually the process ends with a Failed status.⟵ (PaymentExpired(...)) in 3.minutes gets resolved to the following command: (⟶ ScheduleEvent(PaymentExpired(...), now + 3.minutes)) that will be issued to the specialized Scheduling Office.The Saga pattern
As the business process participants are distributed and communicate asynchronously (just like the human actors in the real world!) the only way to deal with a failure is to incorporate it into the business process logic. If a failure happens (a command rejected by the office, a command not processed at all (office stopped), an event not received within the configured timeout), the counteraction, called compensation, must be executed. For example, the creation of an invoice is compensated by its cancellation (see the Ordering Process above). Following this rule, we break the long running conversation (the business process) into multiple smaller actions and counteractions that can be coordinated in the distributed environment without the global / distributed transaction.
This pattern for reaching the distributed consensus without a distributed transaction is called the Saga pattern and was first introduced by the Hector Garcia-Molina in the 1987. A Saga pattern can be implemented with or without the central component (coordinator) (see: Orchestration vs. Choreography). The implementation of the Ordering Process follows the Orchestration pattern - the Ordering Process is managed by an actor, that is external to all process participants.
This pattern for reaching the distributed consensus without a distributed transaction is called the Saga pattern and was first introduced by the Hector Garcia-Molina in the 1987. A Saga pattern can be implemented with or without the central component (coordinator) (see: Orchestration vs. Choreography). The implementation of the Ordering Process follows the Orchestration pattern - the Ordering Process is managed by an actor, that is external to all process participants.
Process Managers and the Coordination Office
The execution of the logic of a particular business process instance is handled by the Process Manager actor. The Process Manager is a stateful / event-sourced actor, just like the regular Aggregate Root actor, except it receives events instead of commands. Just like the Aggregate Root actors, Process Manager actors work in the offices. Both the Command Office (hosting Aggregate Roots) and the Coordination Office (hosting Process Managers) can be started using the OfficeFactory#office method:
office[Scheduler] // start Scheduling Command Office
office[OrderProcessManager] // start Ordering Coordination Office
Source: HeadquartersApp.scala
OfficeFactory#office method: office[Scheduler] // start Scheduling Command Office
office[OrderProcessManager] // start Ordering Coordination Office
Let the events flow
The Coordination Office is expected to correlate the received events with the business process instances using the CorrelationID meta-attribute of the event. Therefore to stream the events from the event store to a particular Coordination Office we need to create a Source (see: Reading events from a journal) emitting only these events that:
1) belong to the domain of the particular business process,
2) were assigned the CorrelationID meta-attribute.
One way to address the first requirement is to create a journal (aggregated business process journal), that aggregates the events belonging to the domain of a particular business process. Some Akka Persistence journal providers may support the automatic creation of journals that group events by tags. Unfortunately, this functionality is not yet supported by the Event Store plugin, that is used by the Akka-DDD. Luckily though, using the Event Store projection mechanism, we can create the journal of the Ordering Process by activating the following projection:
fromStreams(['$ce-Reservation', '$ce-Invoice', 'currentDeadlines-global']).
when({
'ecommerce.sales.ReservationConfirmed' : function(s,e) {
linkTo('order', e);
},
'ecommerce.invoicing.OrderBilled' : function(s,e) {
linkTo('order', e);
},
'ecommerce.invoicing.OrderBillingFailed' : function(s,e) {
linkTo('order', e);
},
'ecommerce.invoicing.PaymentExpired' : function(s,e) {
linkTo('order', e);
}
});
Source: order-process.js
Now, the events from the order journal need to be assigned the CorrelationID and directed to the responsible Coordination Office. What is important and challenging though, is to ensure that the events get delivered in a reliable manner.
CorrelationID meta-attribute of the event. Therefore to stream the events from the event store to a particular Coordination Office we need to create a Source (see: Reading events from a journal) emitting only these events that:2) were assigned the
CorrelationID meta-attribute.fromStreams(['$ce-Reservation', '$ce-Invoice', 'currentDeadlines-global']).
when({
'ecommerce.sales.ReservationConfirmed' : function(s,e) {
linkTo('order', e);
},
'ecommerce.invoicing.OrderBilled' : function(s,e) {
linkTo('order', e);
},
'ecommerce.invoicing.OrderBillingFailed' : function(s,e) {
linkTo('order', e);
},
'ecommerce.invoicing.PaymentExpired' : function(s,e) {
linkTo('order', e);
}
});
order journal need to be assigned the CorrelationID and directed to the responsible Coordination Office. What is important and challenging though, is to ensure that the events get delivered in a reliable manner.Reliable events propagation
By reliable delivery I mean effectively-once delivery, which takes place when:
- message is delivered at least once,
- message is processed (by the destination actor) exactly-once,
- messages get processed (by the destination actor) in the order they were stored in the source journal.
Effectively-once delivery (a.k.a. The Business Handshake Pattern) can easily be accomplished if the sender keeps track of the "in delivery" messages and the receiver keeps track of the processed messages. The implementation of the pattern becomes straightforward if both the sender and the receiver are event-sourced actors.
For more detailed explanation of how the reliable delivery gets achieved, please refer to the Reliable Delivery Akka-DDD wiki page.
In our scenario, we already have the event-sourced Process Manager on the receiving side (the Coordination Office is just a transparent proxy). The missing component is the event-sourced actor on the sending side. As it is an infrastructure level component, it will automatically be created by the Akka-DDD framework, just after the Coordination Office gets started. The overall behavior of the actor that needs to be created matches the concept of the Receptor — a sensor that reacts to a signal (stimulus), transforms it and propagates (stimulus transduction). The Akka-DDD provides the implementation of the Receptor that supports reliable event propagation, including the back-pressure mechanism.
Receptor
A Receptor gets created by the factory method based on the provided configuration object. The configuration can be built using the simple Receptor DSL.
A Receptor actor is a durable subscriber. During the initialization, it is subscribing (by itself) to the event journal of the business entity that was provided as the stimuliSource in the configuration object. After the event has been received and stored in the receptor journal, the transformation function gets called and the result gets sent to the configured receiver. If the receiver address is to be obtained from an event, that gets propagated, then the receiverResolver function should be provided in the configuration.
One might question the fact that the same events get written twice into the event store (first time to the office journal, second time to the receptor journal). I would like to clarify, that in fact this does not happen. The receptor is by default configured to use an in-memory journal and the only messages that get persisted are the snapshots of the receptor state. The snapshots get written to the snapshot store on a regular basis (every n events, where n is configurable) and contain the messages awaiting the delivery receipt.
stimuliSource in the configuration object. After the event has been received and stored in the receptor journal, the transformation function gets called and the result gets sent to the configured receiver. If the receiver address is to be obtained from an event, that gets propagated, then the receiverResolver function should be provided in the configuration.n events, where n is configurable) and contain the messages awaiting the delivery receipt.Coordination Office Receptor
Having learned how to build a receptor, it should be easy to understand the behavior of the Coordination Office receptor by examining its configuration. As we can see, the receptor reacts to the events, coming from the aggregated process journal, adds the CorrelationID meta-attribute to the event message and propagates the event message to the Coordination Office representative actor. The name of the aggregated process journal and the CorrelationID resolver function get retrieved from the ProcessConfig object — an implicit parameter of the office factory method.
To summarize, the Coordination Office receptor gets automatically created by the Akka-DDD framework, based on the configuration of the business process.
So, let's take a look at the OrderProcessConfiguration:
implicit object OrderProcessConfig extends ProcessConfig[OrderProcessManager]("order", department) {
def correlationIdResolver = {
case ReservationConfirmed(reservationId, _, _) => reservationId // orderId
case OrderBilled(_, orderId, _, _) => orderId
case OrderBillingFailed(_, orderId) => orderId
case PaymentExpired(_, orderId) => orderId
}
}
The aggregated process journal is given the name: order. The correlationIdResolver function returns the CorrelationID from the orderId attribute of the event, for all events, except the ReservationConfirmed. For the ReservationConfirmed event, the CorrelationID / order ID must be generated, because the Ordering Process is not yet started, while the ReservationConfirmed event is being processed.
CorrelationID meta-attribute to the event message and propagates the event message to the Coordination Office representative actor. The name of the aggregated process journal and the CorrelationID resolver function get retrieved from the ProcessConfig object — an implicit parameter of the office factory method. implicit object OrderProcessConfig extends ProcessConfig[OrderProcessManager]("order", department) {
def correlationIdResolver = {
case ReservationConfirmed(reservationId, _, _) => reservationId // orderId
case OrderBilled(_, orderId, _, _) => orderId
case OrderBillingFailed(_, orderId) => orderId
case PaymentExpired(_, orderId) => orderId
}
}
order. The correlationIdResolver function returns the CorrelationID from the orderId attribute of the event, for all events, except the ReservationConfirmed. For the ReservationConfirmed event, the CorrelationID / order ID must be generated, because the Ordering Process is not yet started, while the ReservationConfirmed event is being processed.Message flow - the complete picture
After the initial event has been received and processed by the Process Manager, the business process instance gets started. The business process will continue, driven by the events. The events will be emitted as soon as the commands, issued by the Process Manager, get processed in the responsible Command Offices.
The following diagram visualizes the flow of the commands and events within the system that occurs when the business process is running.


Business process journal
Before reacting to an event, the Process Manager writes the event to its journal. The journal of a Process Manager is de facto a journal of a business process instance - it keeps the events related to particular business process instance in order they were processed by the Process Manager.
Ordering Process - an alternative implementation (Event Choreography)
Instead of giving the responsibility for the business process execution to the single, external business entity (the Ordering Process is managed by a Process Manager, operating in the Headquarters subsystem), we could let the process emerge by allowing more direct communication between the offices. For example, to send the CreateShipment command to the Shipping Office in reaction to the OrderBilled event coming from the Invoicing Office we could register a simple Receptor in the Shipping subsystem. In the same way, we could implement other interactions required by the Ordering Process and thus make the Headquarters subsystem obsolete.
The overall event flow could be modeled as presented on the following diagram:
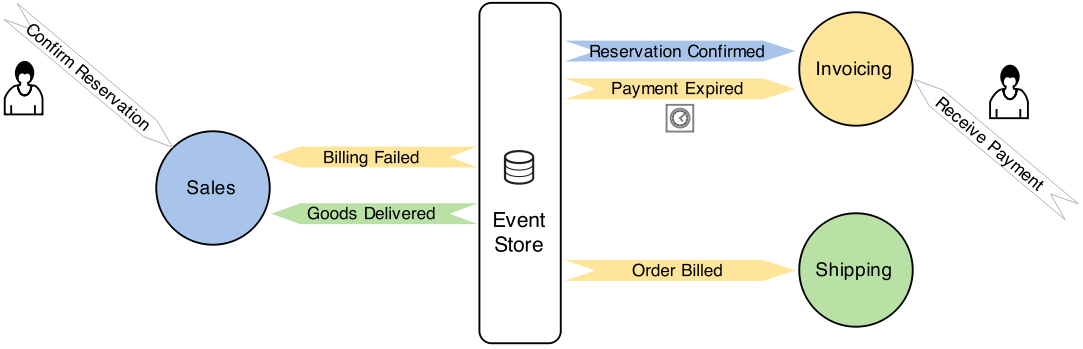 We can find this alternative approach to the implementation of the Ordering Process in the previous version of the ddd-leaven-akka-v2 project. The
We can find this alternative approach to the implementation of the Ordering Process in the previous version of the ddd-leaven-akka-v2 project. The Headquarters subsystem did not exist back then. In the Shipping subsystem, you can find the implementation of the Payment Receptor, that I described above.
Headquarters subsystem), we could let the process emerge by allowing more direct communication between the offices. For example, to send the CreateShipment command to the Shipping Office in reaction to the OrderBilled event coming from the Invoicing Office we could register a simple Receptor in the Shipping subsystem. In the same way, we could implement other interactions required by the Ordering Process and thus make the Headquarters subsystem obsolete.Headquarters subsystem did not exist back then. In the Shipping subsystem, you can find the implementation of the Payment Receptor, that I described above.